
It is commonly known that Serverless Computing has emerged as an agile environment of alternate execution while having many inherent scaling capabilities. The Function as a Service [1] approach, aims to apply the serverless scope also in the way application logic is created, embedded and executed. Currently though, the size of FaaS applications is rather small, indicating that approximately 82% of them have only up to 5 functions in the workflow [2], while at the same time native orchestration mechanisms of FaaS toolkits typically present significant limitations.
PHYSICS platform doesn’t only utilize Node-Red visual-flow tool for its orchestration needs but also OpenWhisk’s ( open-source FaaS platform ) built-in sequence operator. This gave us the trigger to investigate and measure the performance overheads that derive from each orchestration strategy of PHYSICS platform but also to calculate the percentage of useful computational time for each scenario. We created 3 different cases (modes) that apply to PHYSICS’s needs for orchestration:
Mode1: The first observed mode is the Sequence Operator for OpenWhisk runtime functions, meaning both executions and orchestrations of function-sequences we created are located on OpenWhisk exclusively.

Mode2: The second observed mode is a variation of the first, where this time function workflow is created in Node-RED and deployed within a custom Docker function image. The executions as well as the orchestration, are handled by Node-RED, while all functions execute and reside in the same container.
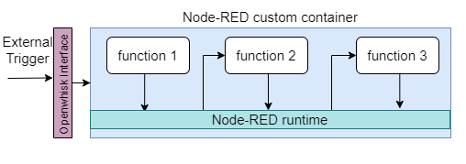
Mode3: The third and finally observed mode derives from the parallelization needs of PHYSICS platform. In this scenario Orchestration flow that is inside Node-RED invokes functions deployed on the OpenWhisk environment, which consequently means the flow acts as a generic orchestrator while the external containers are the main execution environment.

As for the experiment itself:
- We created the artificial delay functions a priori, already knowing their delay, which was 1000ms. Those Functions created sequences with range varying from 1-25 with a step of 5.
- We used warm containers to avoid cold start latency
- One client request was active per time
- Actions were exposed as web actions
- Each measurement was performed with 40 repetitions
The measured time was the inter-function communication delay or orchestration delay, which is the pure baseline delay from a hop of one function to the next in the sequence.
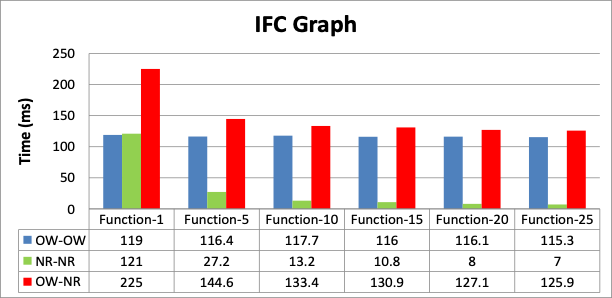
- For OW-OW we can use the average overhead time per function, given that this is independent of the number of functions used
- For NR-NR and OW-NR the initialization time significantly affects the average produced, as the number of functions grows
In order to be more precise we created a mathematical model to describe each mode, with GNU Octave’s Ordinary Least Squares function. The functions that derived from that analysis are the following:

As a next step, we created parametrized plots that arise from the previous mathematical equations, for different function sequences and inner function delays, in order to observe how the estimated total execution differs for different function numbers and delays.
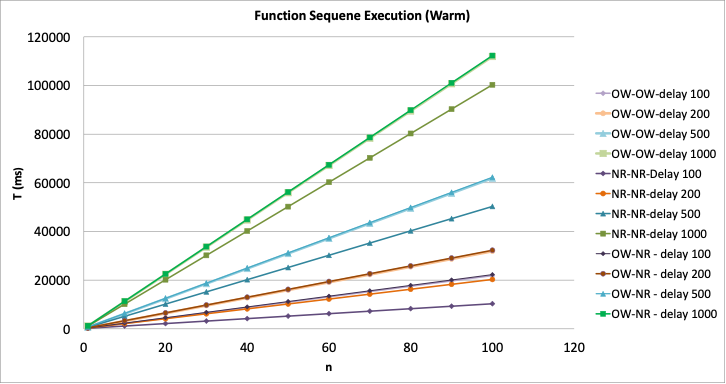
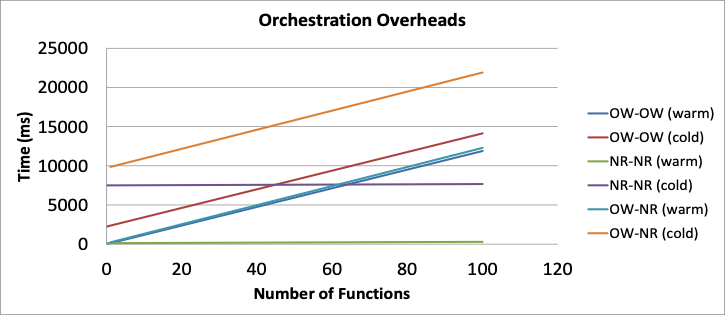
The 40 functions is considerably high in cold start case, though NR-NR in warm executions is always better
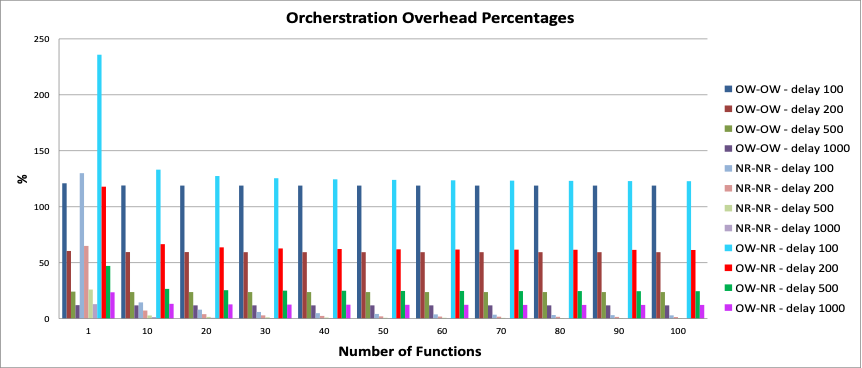
- The NR-NR mode presents the greatest benefits, having under 10% from as low as 10 functions in the sequence and even for small function delays of 100 and 200 milliseconds, with a minimum of 0.29% for 100 functions in the 1000 millisecond case
By dealing with the problem of Orchestration Overheads both theoretically and practically we concluded to the following:
- OpenWhisk’s Orchestration Time is primarily due to warm container reuse time and this delay is unavoidable since in this mode we are not able to implement both orchestration and function logic in the execution container
- The proposed Node-RED orchestration aids in minimizing the needed containers which is basically the biggest part of the delay
- The third mode (hybrid) is only suitable for parallelization needs
- The artificial sleep functions we created, can be replaced with more complex workflows since the baseline time is around the same
- Enabling easier orchestration both functionally and performance-wise can help increase the observed number of functions
All the data and links used for the experiment can be found in the following links:
- https://physics-faas.eu/
- https://hub.docker.com/r/pekoto/noderedaction
- https://flows.nodered.org/flow/f0795ad9f25ad2affcadb8deb305fdf3/in/VOf-0UrN5e2j
- https://hub.docker.com/r/pekoto/owmode3
- https://github.com/pekoto4349/measurements
For more information, please refer to the following publication:
George Kousiouris, Chris Giannakos, Konstantinos Tserpes and Teta Stamati, 2022, Measuring Baseline Overheads in Different Orchestration Mechanisms for Large FaaS Workflows. In Companion of the 2022 ACM/SPEC International Conference on Performance Engineering, April 9–13, 2022, Bejing, China, DOI: 10.1145/3491204.3527467


